¿Es la Golden Visa en España un pase dorado al paraíso inmobiliario? Todo sobre la Golden Visa en España: inversión, residencia y
More

¿Es la Golden Visa en España un pase dorado al paraíso inmobiliario? Todo sobre la Golden Visa en España: inversión, residencia y
More
¿Dónde puedo buscar cupones de descuento? 🤑 Mejores descuentos, chollos y cupones gratis en Internet 🛒✨ ¿Cómo puedo empezar a ahorrar con
More
Radonspain consigue evitar la barrera para el radón en las naves logísticas Son muchos promotores los que a día de hoy, cumpliendo
More
Venta de neumáticos con tecnología innovadora La innovación en neumáticos ha sido un componente crucial en la evolución constante de la industria
More
Los usos del walkie talkie en pleno siglo xxi Aunque los walkie talkies no se pueden considerar un invento reciente, sí hay
More
El Retorno del Servicio Militar en Occidente: Una Jugada por la Seguridad ante la Amenaza de Rusia Países Occidentales Reinstauran el Servicio
More
Los Motores Más Fiables con lo Último en Tecnología: Una Mirada a la Excelencia Mecánica 🚗💡 🚗💡 Los motores más fiables con
More
¿Cómo se usa realmente un extintor? Disponer de un extintor de incendios a mano es una herramienta crucial que puede ayudar a
More
Conoce la mejor opción para optimizar tu sitio web WordPress ¿Necesitas ayuda con tu sitio web WordPress? Avanlok es tu mejor opción.
More
Aumenta el número de españoles con seguro de defunción Casi el 47% de los españoles contaban con un seguro de vida que
More
El Futuro de la Seguridad y Prevención de Riesgos Laborales: Un Enfoque Innovador. La prevención de riesgos laborales es un aspecto fundamental en cualquier
More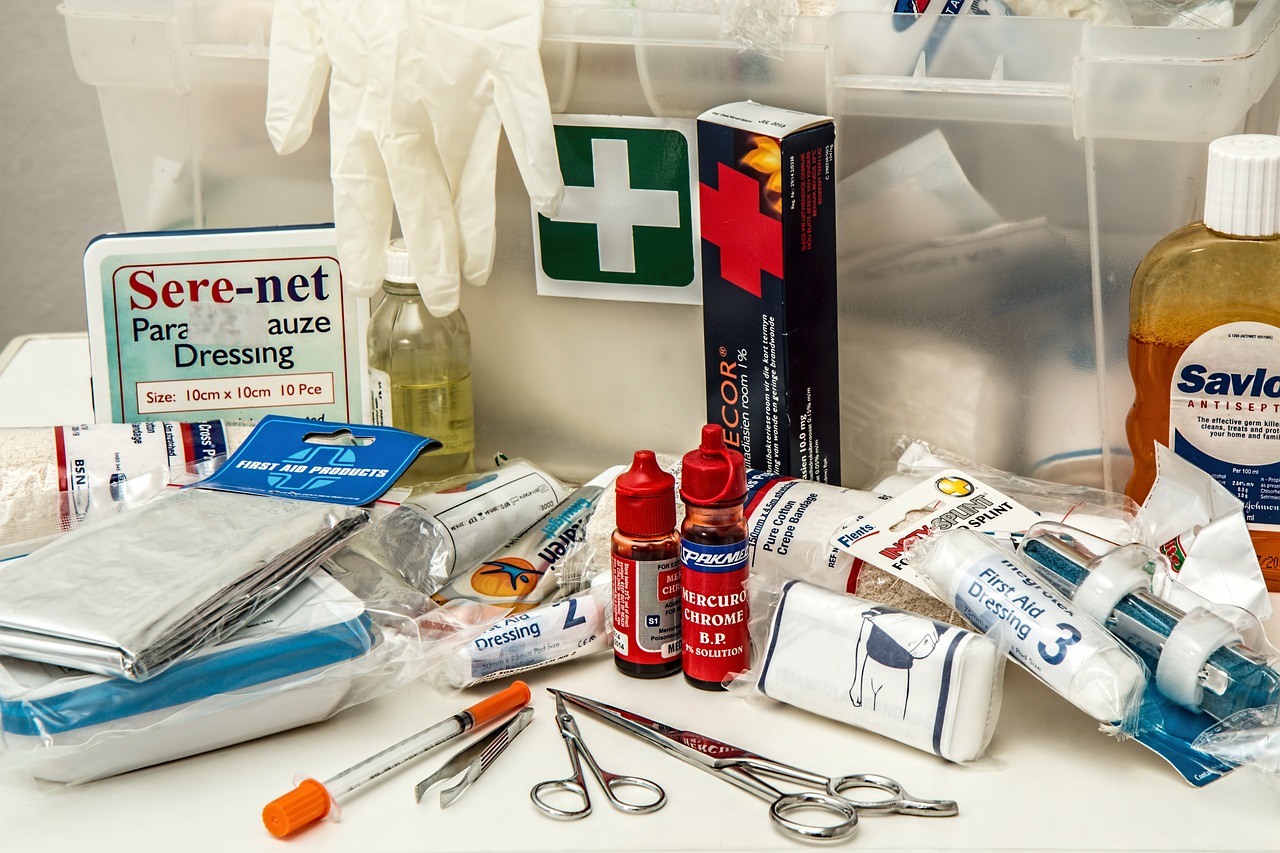
Salud eficiente gracias a la distribución estratégica de equipamiento En el complejo mundo de la atención médica, la distribución eficiente de equipamiento
More
Viaje al Futuro con AXA: Seguro de Coche y Predicciones que No Creerías Posibles. Explora el Futuro con AXA – Innovación en
More
¡Adiós Llaves, Hola Futuro! Descubriendo la Cerradura Inteligente U200 de Aqara. Explorando la Cerradura U200 de Aqara – Tu Hogar al Alcance
More
¿Cómo son las situaciones actuales en la banca en torno a productos financieros que son reclamados? Hablemos de la banca IRPH, Euribor
More
El Futuro del Tráfico: Entre la Burocracia y la Innovación Tecnológica. Así es el futuro de la seguridad vial. En la era
More
Eliminar el amianto para salvaguardar la salud En la búsqueda constante de ambientes más seguros y saludables, la importancia de eliminar el
More
Cómo Sobrevivir con el Salario Mínimo y No Morir en el Intento: Estrategias de Ahorro Seguro. En la era de los ajustes
More
¿Cómo los Seguros de Coche Están Evolucionando con la Tecnología? Seguros de Coche del Futuro. En la actualidad, la intersección entre la
More
5.5G: Más rápido, más allá, ¿pero mejor? ¡Averígualo! 5.5G: La evolución tecnológica que no sabías que necesitabas. Buenos días, soy Johnny Zuri
More
El sector del turismo activo se ha expandido significativamente, ofreciendo a los aventureros experiencias únicas y emocionantes alrededor del mundo. Desde el
More
Viaje en el Tiempo: La Evolución de la Seguridad desde los Modelos Ford T. Viaje en el Tiempo con Cinturón: Cómo el
More